Laurel Woods, Lindsey Mardona, Ulysses Pascal.
1. Introduction
The Holocaust was the state-sponsored genocide of European Jews and millions of others by the German Nazis during World War II. This global event tore apart families and involved far reaching processes of displacement, concentration, deportation, dislocation, and relocation. As a result of its nature, experiences and survivor stories of the Holocaust involve both widely shared traumas, as well as unique, heterogeneous individual testimonies. Thus, the memories associated with survivors’ personal experiences through the events of the Holocaust are incredibly emotionally complex and nuanced.
Historians and researchers have attempted to study the scale and complexity of the Holocaust through oral histories and testimonies. In 1954, David Boder studied the frequency and magnitude of trauma in oral testimonies by manually annotating transcripts from oral histories. Boder’s study used an exponential scale to categorize traumata. The scale took into consideration multiple dimensions of experience, including whether trauma events were witnessed directly or indirectly.
Contemporary sentiment analysis tools lack the level of nuance and dedication to detailed description that Boder exhibited. Sentiment analysis tools are limited in multiple dimensions, including inabilities or ineffective accounts for tone, sarcasm, negations, comparatives, and multilingual data, and these weaknesses are enhanced especially when applied to complex texts in digital humanities.
More recently, Blanke et al. (2020) used neural networks to assign positive or negative sentiments to testimony segments. This approach to sentiment analysis involved using a combination of dictionary based methods and machine learning to construct a dataset of negative and positive text segments drawn from Holocaust testimonies. Blanke et al discovered negative word embeddings associated with places. Specifically, Blank et al investigated what words are associated with “camp” and they reported that “The model of negative memories includes the camps ‘Buchenwald’, ‘Auschwitz’, ‘Mauthausen’, ‘Dachau’, etc.”
While these findings reinforce our knowledge of the atrocious events of the Holocaust, high level representations of associations between words does little to bring into relief the complexity of affect surrounding these sites. As Kushner has argued, “For survivor oral testimony to be utilized to its full potential” it would require “the strands of history and memory to be woven together to show the full complexity of survivor identity.” It should not be overlooked that while many gruesome acts occurred at camps, they were also places where many survivors lived for several years and experienced a wide range of emotions, despite the traumatic conditions to which they were subjected. In reading testimonies, it is possible to find more emotionally complex and multidimensional depictions of camp life. For example, in a testimony from Holocaust survivor Isaac Levy, he recalls:
One dynamic little man by the name of Yossele Rosensaft was the moving, moving figure in this. He was indestructible. He’d been pushed from one camp to another and survived. He stood about 5 foot 2 in his socks, but energy beyond recognition.
(File: 8610, Time Code: 0:41:00)
It is important to acknowledge that camps were not only sites of genocide, but they were also sites of liberation. As expressed in Sabina Wagschal’s testimony:
Yes. She was liberated by the Russians. They came to the camp. And the Russians, in her case, were her liberators.
(File: 1965, Time Code: 1:17:00)
Furthermore, while concentration camps and death camps are a common site discussed in Holocaust testimonies, these were not the only camps that Holocaust survivors experienced. Another crucial element of survivor’s experiences are refugee camps, which also cannot be reduced to negative memories. Malka Baran recalls memories from the refugee camp in their testimony as follows:
(File 24470, Time Stamp: 1:40:00)
A little bit. Uh, I studied English at home a little bit and after the camps a little bit. I even taught a little bit of English in the B camp, in the displaced person camp. And when I came here, I studied, uh, very seriously in college, though I– and I like to read, so I read English books. That helped me a lot.
Thus the finding that sentiment is embedded in the language that surrounds places should be understood not as a definitive reduction of place to sentiment, but rather as an opportunity to study the relationship between sentiment and place in more depth. Such a study should take into consideration that places are neither passive nor static containers of history. Places and their spaces are active and dynamic sites that can both change and produce changes. As Knowles, Cole and Giordano (2014) argue, “Holocaust was implemented through space and not merely in space.” With these concerns in mind, the focal point of our interest is: how can digital humanities address the complexity and geographic scale of emotional experiences of Holocaust survivors?
2. Research Questions
In order to investigate this interest, we highlighted three additional research questions to focus on:
- How do the sentiments associated with places vary over the narrative time of a testimony?
- What are the limits of sentiment analysis for understanding memories of place in Holocaust testimonies?
- How was affect geographically dispersed during the Holocaust? Did the experiences of the Holocaust vary with respect to geographic places?
3. Method
3.1. Data
We analyzed 984 English transcripts of Holocaust survivors from the Shoah foundation. These transcripts were formatted as CSVs separated into chunks of text and coded by the survivor, interviewer, or a third party speaking. There was also associated metadata that correlated timestamps to topics of each transcript.
3.2. Manual Sentiment Annotation
We manually annotated 864 randomly extracted segments of transcripts as “Positive”, “Negative”, or “Neutral” sentiment. To construct a dataset for training and evaluation, we created a script that randomly selected one of the 984 testimonies. From this testimony, the script would then extract a random text segment from one of the interviews. Text segments are answers to interview questions that are 1 minute or less. The length of text segments ranges from one word to several sentences. We considered using single sentences or everything said within 1 minute as potential units of analysis. However, as answers to interview questions, text segments are more meaningful units than single sentences or what is said after a fixed interval of time.
After selecting a segment, the script displays the segment and prompts the annotator for input. Only “POSITIVE”, “NEGATIVE”, or “NEUTRAL” are allowed. If the annotator responds with “NEGATIVE” or “POSITIVE”, then the script asks “How negative?” or “How positive?” on a scale from “Somewhat”, to “Very”, to “Extremely”. Though we did not use the degree of positivity or negativity in the analysis, we found it ethically necessary to allow the annotator to acknowledge the range of positivity and negativity in the data.
Holocaust testimonies include a very wide range of negative and positive sentiment. For example, several testimonies document mass death in concentration camps.. One of the more extremely negative passages is the following description of life under the Nazi regime:
And the sight was absolutely– I don’t know if you can believe it or not. What happened was, the people who got killed, they were dead, of course. The people who were wounded, they wouldn’t let anybody go there and help them. And they were crying and moaning. They were begging to be shot. The– the Germans wouldn’t let anybody near them so as to discourage others from breaking out.
(File num: 7739: Time: 0:52:00)
This passage is extremely negative and contains themes of mass death, genocide, and intense pain and suffering. However, not all negative sentiments are equally negative. Holocaust testimonies also contain other forms of negative sentiment. In the following passage a survivor describes attempting to acclimate to life in America:
I came here to America, and I– my uncle invited me as a guest for a week. There, I stayed. And he wanted me to live on the farm. He wanted to rent the farm, or maybe even buy for me a farm– something. And I didn’t want to live in a– in a village. I said, I had enough village life.
(File num: 8753, Time Stamp: 2:04:00)
In this passage, the survivor is clearly expressing a negative sentiment of displeasure and the feeling not enjoying a way of living. Compared to the first passage, this passage is not nearly as negative but it is not positive or neutral either. From an ethical standpoint it can feel strange to group the most attrocious events of the holocaust with comparatively minor forms of negativity. We found it necessary to include a negativity and positivity scale in the annotation processes to mentally account for these differences.
We labeled 864 text segments. These labeled segments amounted to 354 “Negative” sentiments, 314 “Neutral” sentiments, and 196 “Positive” sentiments. These manual labels were used to evaluate different sentiment analysis methods, as well as train three models to predict sentiment.
Distribution of Sentiment in Labeled Data

3.3 Data Processing
In our initial processing of the data, we filtered out stopwords, which included common English words with little semantic meaning (e.g. “pardon”) as well as common words that expressed blatant affirmation or dissent, which skewed the sentiment analysis towards positive or negative (e.g. “yes” and “no”). Other words that frequently appeared in the transcripts but provided no relevance to sentiment due to the nature of the testimonies and the cultural background of the survivors being interviewed were labeled as stopwords as well (e.g. “yiddish”, “non-english speech”).
We chose to focus only on the portions of the transcripts where the interviewee was speaking. In order to make this easier, we filtered out any text from speakers other than the survivors in our preliminary data processing. We also transformed all the text into lowercase to standardize it for later sentiment processing purposes.
3.4. Sentiment Analysis
We first attempted a sentiment analysis of the transcripts using two different dictionary based methods. A dictionary-based method essentially treats the input text as a “bag of words” where the order and context is not considered. Words with a positive connotation (e.g. “laugh”) count positively towards the overall sentiment, while words with a negative connotation (e.g. “war”) count negatively towards the overall sentiment. After considering the total number of positive and negative words in a chunk of text, the algorithm outputs a final score that either classifies the text as positive or negative to a certain degree.
3.4.1. Dictionary Based Methods
NLTK Vader
The first dictionary based approach we tried was Vader, which works through the Python Natural Language Toolkit module. Vader gives three separate scores for the amount of positive, negative, and neutral sentiment in a chunk of text. Vader then computes a normalized weighted compound score between [-1, 1] to indicate overall sentiment, with 0 indicating a neutral sentiment. Vader is sensitive to negation, qualifiers (e.g. “like”, “very”), punctuation, and modern slang.
When we ran Vader on our manually labeled data, we got an accuracy score of 53.72%. When we ran Vader on the entire corpus of data, we got the following distribution of predictions:

Vader classified chunks of text as positive or neutral relatively equally, with much fewer chunks of text being classified as negative. Text with the most extreme positive or negative values was typically only a few words in length. However, the average text length for each label was as follows:
NEGATIVE 152.6 wordsNEUTRAL 65.3 wordsPOSITIVE 149.4 wordsThe following chart shows the distribution of compound scores from Vader. 0 represents a neutral score, while values greater than 0 represent a positive sentiment and values less than 0 represent a negative sentiment.

The other dictionary-based method that we used, TextBlob, gave fairly similar results to Vader. Similar to the compound score produced by Vader, TextBlob takes in some text as input and returns a polarity score between -1 and 1 to indicate the degree of negative or positive sentiment. What sets TextBlob apart is its output of a subjectivity score between 0 and 1; this score indicates the level of opinion and personal judgment involved, with 0 being more objective and 1 being more subjective.
TextBlob
When we ran TextBlob on our manually labeled data, we got an accuracy score of 47.34%. Running TextBlob on our entire dataset yielded the following sentiment predictions:
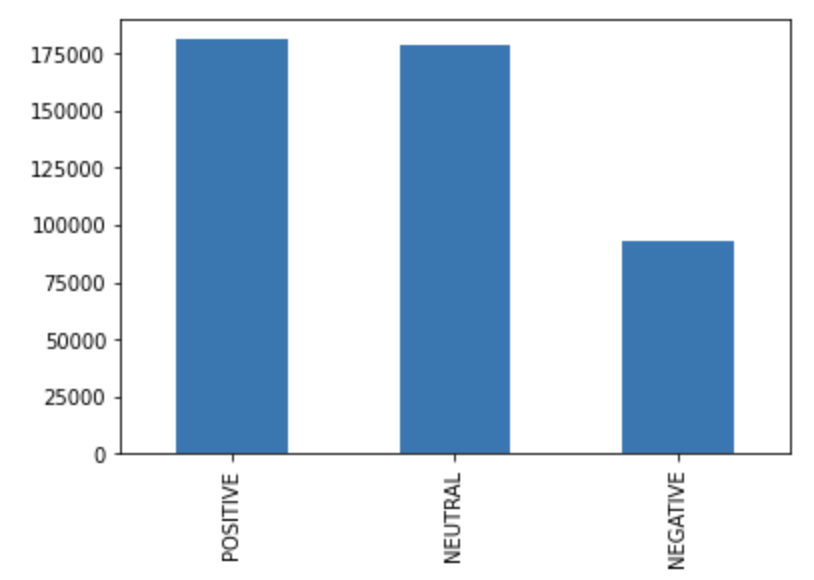
These were fairly similar numbers to Vader, except with fewer negative predictions.
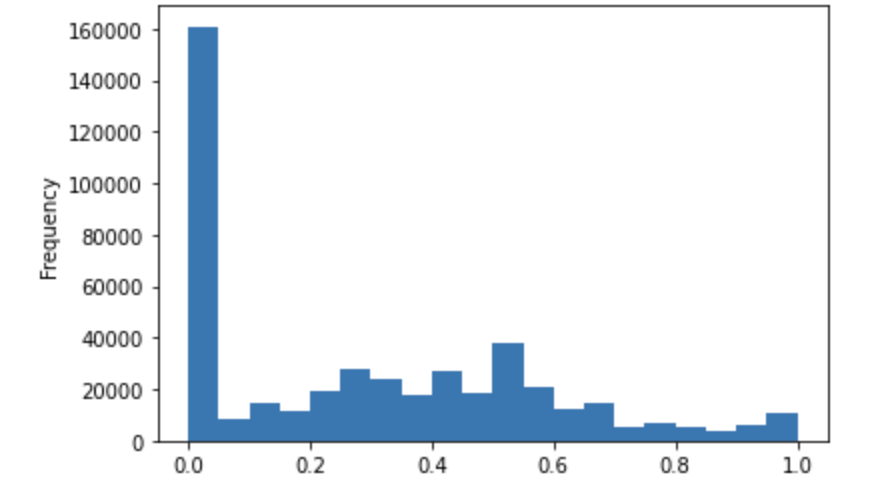
Distribution of TextBlob polarity scores:

Distribution of TextBlob subjectivity scores:
Modified NLTK Vader
After our preliminary analyses, we observed the results and noticed a dissociation between certain words which were given polarity scores in the context of everyday English but held different meanings in the context of the Holocaust. For example, the sentence “People became like animals.” was given a compound score of 0.455 by NLTK Vader, indicating a “Positive” sentiment. This is likely due to the general positive connotation of animals in casual contexts, but in the context of the Holocaust, it is almost certainly more likely that the use of animals is more along the lines of a comparison of human beings to livestock. As a result, we modified the NLTK Vader dictionary to be more specific to our purposes. For example, some of the words that are by default labeled as “Neutral” include “crematorium”, “sewage”, and “gas”. Considering the events of the Holocaust, these are all words that are arguably inherently negative, and thus the most frequent words from testimonies were counted, extracted, manually examined, and appropriately reevaluated in a .csv file of manually labeled lexicons. From doing this, we saw a slight increase in accuracy to the labeled data, from an accuracy percentage of 53.72% (derived from the default Vader dictionary), to 57.99% (with the new dictionary). Running this modified version of NLTK Vader on our entire dataset yielded the following sentiment predictions:
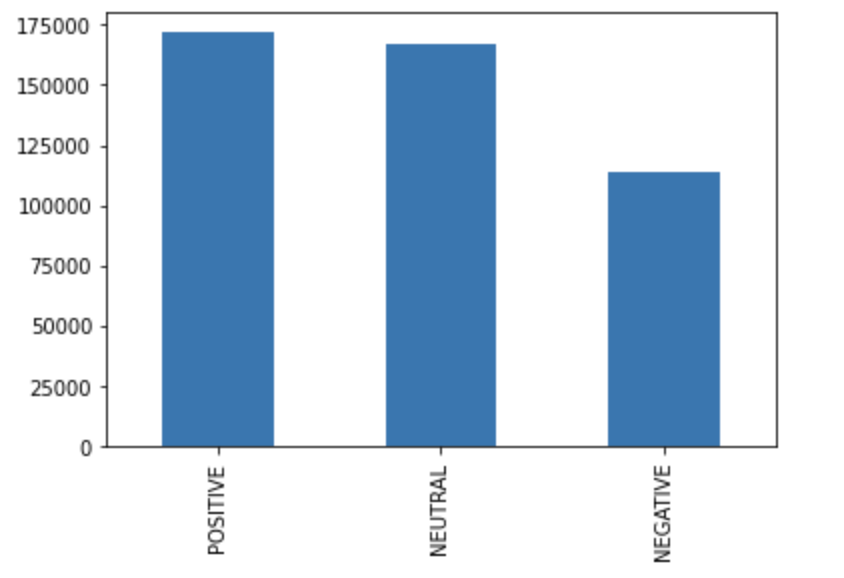
The compound score distribution is visualized below.
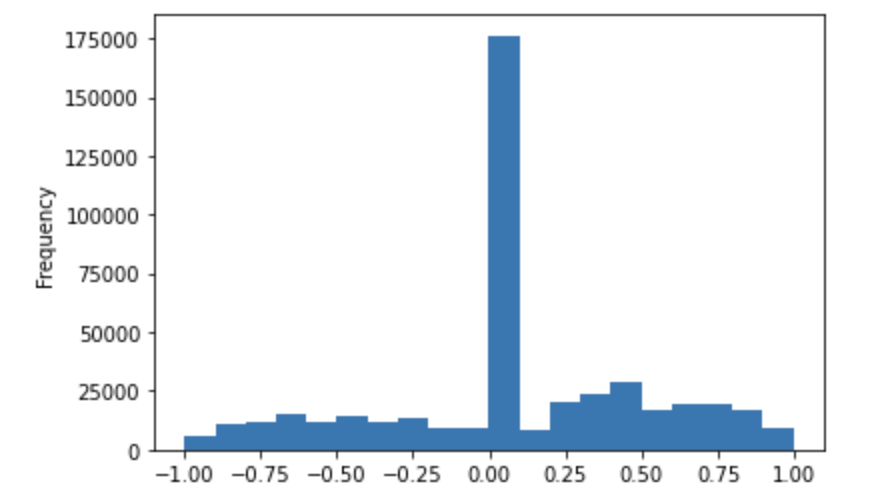
3.4.2. Linear Classifiers
Following our initial analysis using dictionary based methods, we then considered linear classification as an alternative way of analyzing sentiment. Linear classifiers use a linear combination of the features and characteristics of input objects in order to label and classify data. Unlike the dictionary based methods, which contain predefined lexicons of words and their corresponding sentiment polarities, these algorithms require a portion of the labeled data to be used for training, and are afterwards tested on a smaller portion of the labeled data. The two methods we selected for testing were Naive Bayes and Logistic Regression.
Naive Bayes
Naive Bayes classifiers are probabilistic classifiers built on Bayes’ theorem. This theorem can be written in plain English as posterior = prior likelihoodevidence. Specifically, the distribution we used was Multinomial Naive Bayes from the Scikit-learn machine learning library for Python. This distribution is popular in Natural Language Processing (NLP). It uses frequencies to calculate the probability of each item’s classification and it outputs the most likely label.
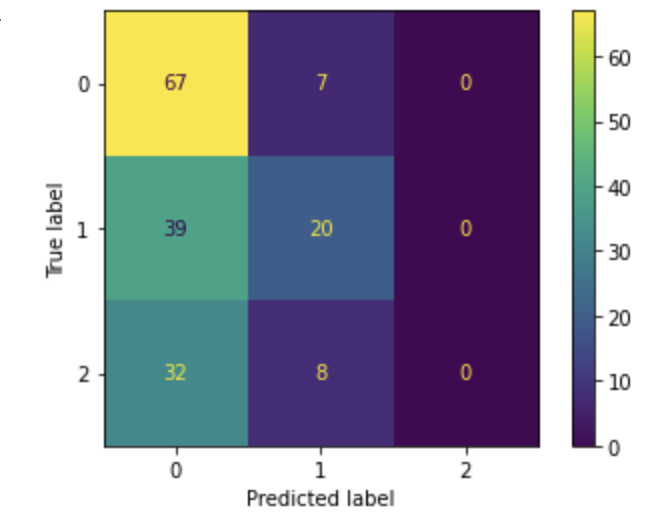
After running the model on the full dataset to generate predictions, we had the following distribution of sentiment predictions:
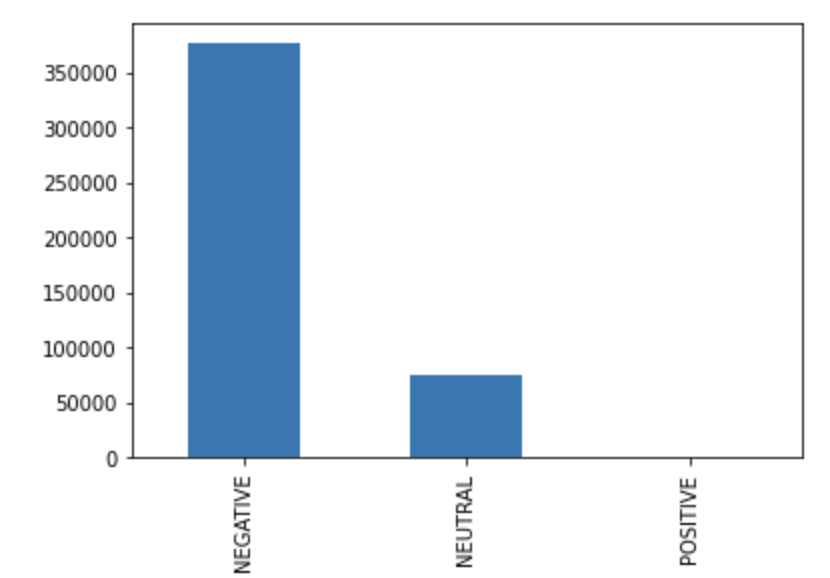
The algorithm did not label any of the testing data as positive, and primarily labeled each segment as negative. When run on all of the transcripts, there were an overwhelming 376,955 segments predicted to be labeled “Negative”, compared to 74,441 “Neutral” labels and 867 “Positive” labels. It is possible that this may be attributed to the limited training data that we had available.
Logistic Regression
We also used a logistic regression model to attempt a sentiment analysis on our data. We used the manually labeled data to fit the model. With an 80% training / 20% testing split on the labeled data, we got only 52.0% accuracy on the test data. The following figure shows the confusion matrix for the test data, with 0 representing Neutral, 1 representing Negative, and 2 representing Positive.
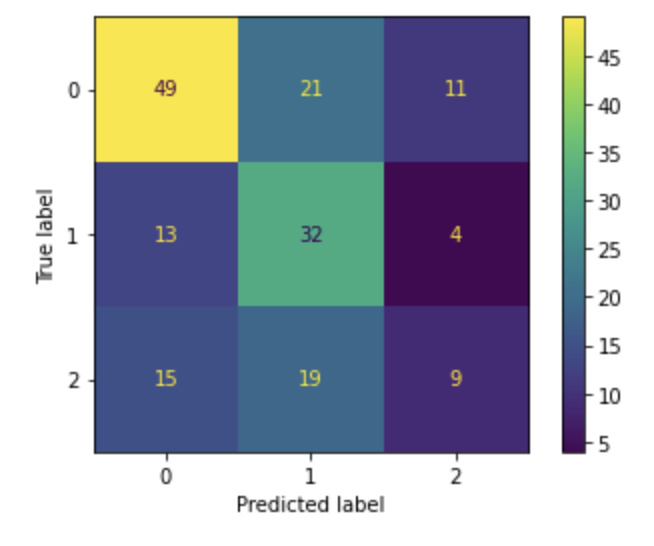
After running the model on the full dataset to generate predictions, we had the following distribution of sentiment predictions:
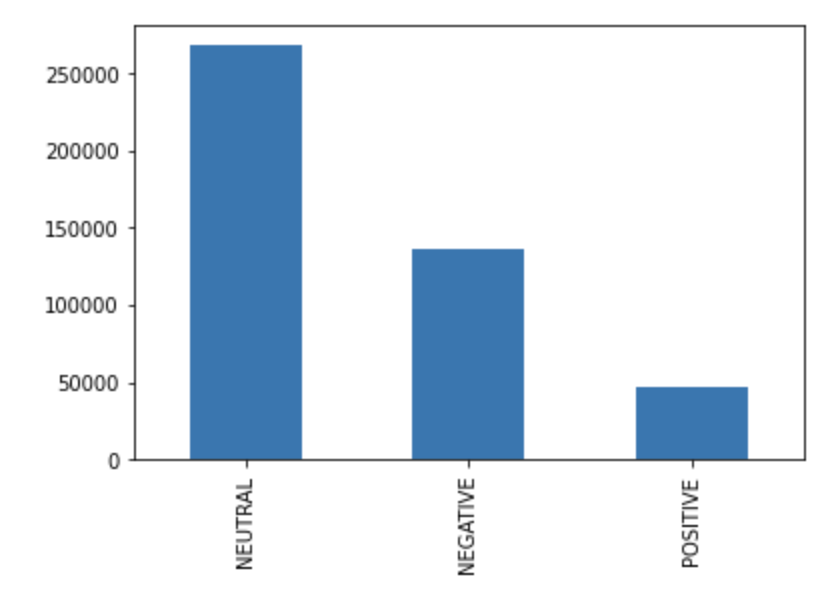
Unlike the dictionary-based methods, the logistic regression model classified most text chunks as Neutral sentiment, and fewer text chunks as Negative or Positive.
3.4.4. Transformer Models
Transformer models are a promising alternative to dictionary based methods and linear classifiers. Transform models are a set of pre-trained weights or parameters produced by training a neural network on a large corpus of text. Each parameter refers to the learned probabilistic relationship between strings of text. GPT-3 is an example of what is called a large language model because it consists of a large number of parameters: 175 Billion parameters. Unlike other neural networks models, such as RNNs, transformer models can be continually re-trained with additional information. When that additional information is domain specific, the process of re-training the model is called fine tuning.
Transformers are capable of many NLP tasks including text generation and text classification. Unlike linear classifiers, which model a relationship between the set of text inputs and the set of labels, transformer models process each text input independently of one another. Given an input sequence, transformers models predict what is the most likely word or set of words to come next in the sequence. The output of a transformer model is conditioned on a text sequence that serves as an input to the model. Large language models, such as GPT-3, are capable of predicting the sentiment of text inputs without fine-tuning, while smaller transformer models, such as GPT-2 require training data to produce usable results.
There are three methods to improve the output of a transformer model: 1) Prompt engineering, 2) Hyper-parameter tuning and 3) Fine-tuning. Prompt engineering attempts to improve the output of a model by changing the input sequence. Because model output is stochastically contingent upon the sequence of prior text, successful deployment of transformer models depends on well designed textual inputs. GPT-3 documentation recommends that the prompt for sentiment analysis should be:
Decide whether a Sentence’s sentiment is positive, neutral, or negative.\n\nSentence:{text} \n\nSentiment:
The sentence “Decide whether a Sentence’s sentiment is positive, negative or neutral” primes the model to classify the following sequence based on positive, negative or neutral sentiments. On a new line, “Sentence:” is completed with a variable that contains the sentence or text to be analyzed. Lastly, “Sentiment:” completes the prompt, and provides a cue that the model can use to complete the text sequence. Additionally, hyper-parameters such as temperature, length, and top_p can be adjusted to optimize the model for sentiment analysis. In this task, the goal is to complete the sequence with one of three possible words: positive, negative or neutral. Therefore low temperature and high top_p values should be used to ensure that the most probable words complete the prompt.
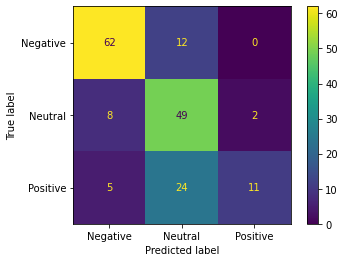
The untrained GPT-3 model accurately classified 70.52% of the labeled test data. Though this result was considerably more accurate than dictionary based approaches, deploying large models requires access to costly computing resources such as multiple high-end GPUs or pay-per-token cloud computing. Using the OpenAI API, the cost of this task was approximately $1 for the combined 172 text segments in the labeled text data. Extrapolating this figure to the larger data sets, it would cost an estimated $500 to deploy GPT-3 on the 86,171 unique text segments in the geo-tagged data set and $9500 for the 1,647,593 text segments in the entire dataset.
Owing to the cost of using large language models, it was not feasible to use GPT-3 on the entire dataset. Smaller transformer models can be run on desktop computers and free GPUs offered by Google in Colab. However, smaller models, such as GPT-2 are not as capable as GPT-3 when it comes to solving NLP tasks without fine-tuning.
Smaller models, such as GPT-2, require a different approach to prompt engineering. Whereas larger models can predict the desired relationship between tokens without examples, smaller models require some examples to complete the task. This approach, called few shot learning, involves constructing 3 to 10 examples of the desired output. These examples are then included in the prompt.
Owing to the high cost of GPT-3, we experimented with the smaller open source GPT-2 model. We used the “medium” sized 355 million parameter version of GPT-2. This is the largest version of GPT-2 that can fit inside a Google Colab instance. With more computing resources it could be possible to use larger open source models, such as the Large 774 million parameter GPT-2 model or the Euther AI GPT-J and GPT-Neox models which are 6 Billion and 20 Billion parameters respectively.
We attempted sentiment analysis with few-shot learning. We used manually annotated data from outside of the test data set to construct a set of examples of sentiment classification. Below is a version of a prompt that includes six example prompts followed by final prompt:
Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: 1920, the 1st-- the 15th of March. Sentiment: NEUTRAL ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: Now, coming back to May 8th, after the Germans left, about 10 o'clock in the morning, [PAUSES FOR 4 SECONDS] a civilian Russian car drove into the camp. The Germans, of course, were gone. The gates were open. Sentiment: POSITIVE ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: So we couldn't swim. I didn't know how to swim. But we took a chance. The water was covering-- if life is [INAUDIBLE]-- covering till our necks. We went by this water, and we came to woods. It was woods, trees with snow, still, in May there. So we laid down. And then-- and we was-- Sentiment: NEGATIVE ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: Oh, sure. Yeah. Sentiment: NEUTRAL ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: And he was bewildered, completely bewildered, and let me in, of course. And his wife was a very pretty Polish girl. And they had a little girl. And they told me-- they could-- somehow, they couldn't have children, so they adopted the little girl. And I told him the story. Sentiment: POSITIVE ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence: So when he came-- so I said, no, that's me. My sister got killed. And his wife got killed. And he had a child nine months old. So he says, you know what? Maybe God-- OK, you're a lot younger than him, 17 years. So he said, you know what? He wants to take me out from the-- from the house. Sentiment: NEGATIVE ######Decide whether a Sentence's sentiment is positive, neutral, or negative. Sentence:{text}Sentiment: One drawback of few shot predictions is that the order of example prompts may bias a model’s output. To optimize few show prediction models, prompts may need to be engineered to randomly shuffle the order of the examples to mitigate the bias. In addition, the number of examples can be varied from 3 to approximately 10. The optimal number examples can be determined experimentally.
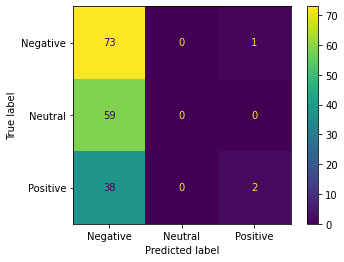
The untrained GPT-2 model accurately classified 43.35% of the labeled test data. The confusion matrix shows that the model over-predicted “Negative” labels while under-predicting both “Neutral” and “Positive” labels. We experimented with varying the number of example classifications in the prompt and found that 6 example classifications tended to produce the best results. More rigorous testing and example selection may marginally increase the results of few shot predictions. However, at 43.35% accuracy, GPT-2 was outperformed by the Vader models and Logistic regression.
To improve the accuracy of GPT-2 we fine-tuned the model. Unlike prompt engineering, fine-tuning involves training the model and updating the model’s weights. The approach we adopted involved constructing a dataset of example prompts from the labeled training dataset. These example prompts were concatenated into a single text file and used to fine tune the model.
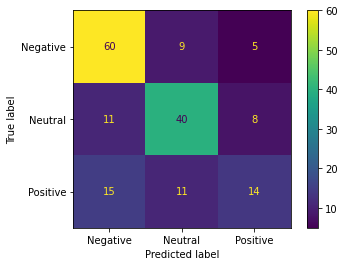
Fine tuning the model resulted in a large increase in accuracy. The fine-tuned model was able to accurately classify 65.89% of the labeled test data. Unlike the non-fine-tuned model, the fine-tuned model was capable of predicting sentiments in each sentiment category. Though the fine-tuned model did not outperform GPT-3, running the fine-tuned GPT-2 model is free. With more training data, it may be possible to increase the accuracy of the model’s performance.
3.5. Location Extraction with Named entity recognition of places and Geocoding
To associate text segments with geographic places we used the open source library Spacy to extract named entities of tagged locations or geopolitical entities. Named entities were then georeferenced using the google maps API. This process resulted in 144,361 geocoded entities and 86,171 unique textual contexts. Using text data as a key, the geocoded data was joined with the sentiment analysis results from the fine-tuned GPT-2 model. The resulting dataset included every location mentioned in 984 testimonies and the predicted sentiment of the textual context that surrounds each location instance.
4. Analysis
4.1. Sentiment and Narrative Time
We analyzed the average sentiment values from the Vader approach over the course of each testimony. For this, we calculated the time percentage of each testimony by dividing the timestamp of each text chunk by the total duration of the testimony. We then averaged the sentiment values for a certain time percentage (to 2 decimal places) over all 984 transcripts. The line chart below shows these average sentiment scores.
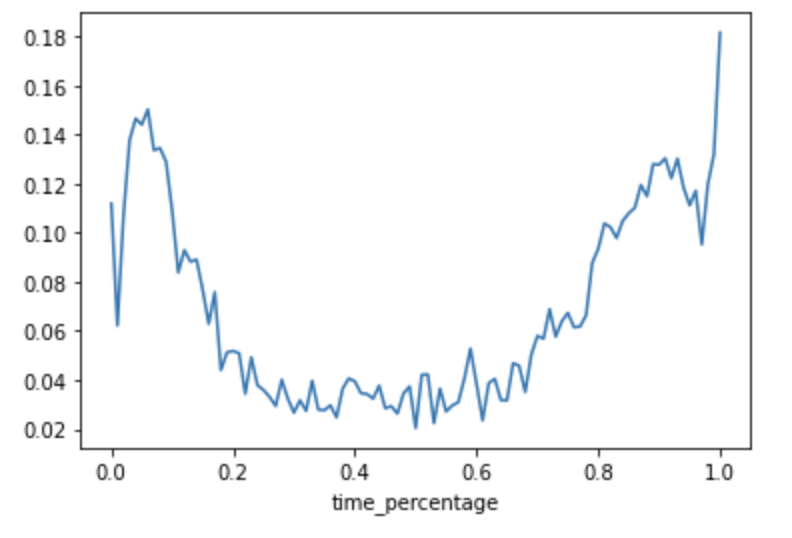
As seen in the chart, sentiments are generally more positive in the beginning and end of the testimony and more negative towards the middle. This likely follows the format of testimonies starting by talking about childhood and pre-war experiences, and then discussing their experiences during the war, which are much more traumatic. The end of the testimonies typically talk about post-war life and family members, which is a comparatively more positive sentiment.
The following chart shows the counts of text chunks predicted as “Positive”, “Neutral”, or “Negative” over narrative time.
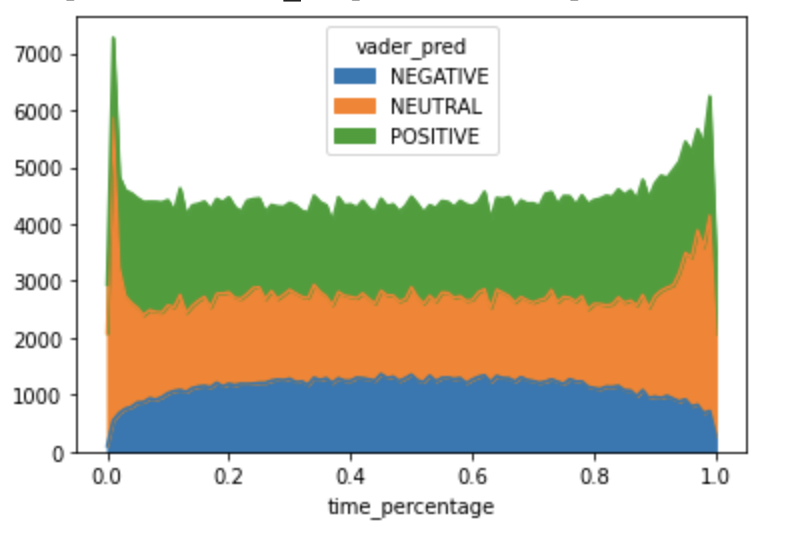
The chart follows the previous results of average sentiment score with more neutral text chunks in the beginning and end of the testimonies, and more negative text chunks towards the middle of the testimonies.
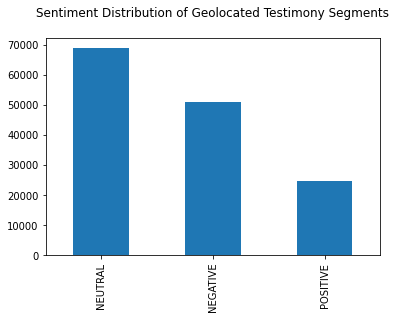
4.2. Sentiment Analysis of Geocoded Testimony Segments
To prepare the data for mapping, each context that contains a location was merged with the results of GPT-2 (fine-tuned) sentiment analysis. 47.72% of geocoded entities occurred in neutral contexts, 35.26% in negative contexts and 17.01% positive positive contexts.
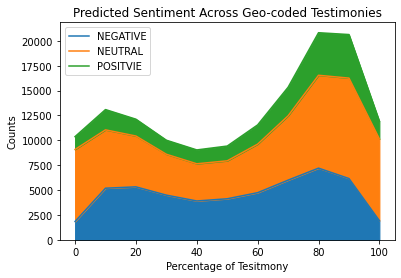
Compared to the Vader results, there appears to be two moments toward the beginning and the end of the testimonies where negative sentiment increases. In the 70% to 80% range there is an increase in the positive, negative and neutral sentiments, with neutral sentiments being the most pronounced.
| Location | NEGATIVE | NEUTRAL | POSITIVE | Total | NEGATIVE | NEUTRAL | POSITIVE |
| America | 1247 | 1246 | 977 | 3470 | 35.94% | 35.91% | 28.16% |
| Berlin | 889 | 985 | 345 | 2219 | 40.06% | 44.39% | 15.55% |
| England | 834 | 1142 | 499 | 2475 | 33.70% | 46.14% | 20.16% |
| Europe | 793 | 699 | 434 | 1926 | 41.17% | 36.29% | 22.53% |
| France | 985 | 1006 | 429 | 2420 | 40.70% | 41.57% | 17.73% |
| Germany | 4340 | 4160 | 1348 | 9848 | 44.07% | 42.24% | 13.69% |
| Hungary | 1061 | 1261 | 323 | 2645 | 40.11% | 47.67% | 12.21% |
| Israel | 1998 | 4299 | 1178 | 7475 | 26.73% | 57.51% | 15.76% |
| New York | 693 | 1390 | 620 | 2703 | 25.64% | 51.42% | 22.94% |
| Poland | 4078 | 4806 | 1256 | 10140 | 40.22% | 47.40% | 12.39% |
| Russia | 1537 | 1680 | 466 | 3683 | 41.73% | 45.61% | 12.65% |
| the United States | 995 | 1243 | 952 | 3190 | 31.19% | 38.97% | 29.84% |
| Vienna | 808 | 1046 | 326 | 2180 | 37.06% | 47.98% | 14.95% |
| Warsaw | 1831 | 1734 | 487 | 4052 | 45.19% | 42.79% | 12.02% |
Across all documents, “Poland”, “Germany”, “Israel”, “Warsaw” and “Russia” were the most commonly tagged locations. Text contexts surrounding “Germany” were tagged ‘NEGATIVE’ more often than contexts surrounding any other location. However, Germany was associated with the most ‘POSITIVE’ tags as well. Whereas the contexts surrounding Poland were the most associated with “NEUTRAL’.
4.3. Visualization
To categorize geolocated text segments we used metadata from the Shoah Foundation. Rule based algorithm extracted dates from metadata. For time codes with no explicitly dated metadata, historically charged terms such as “concentration camp” and “liberation” were counted and used to estimate the time period of the text segment.
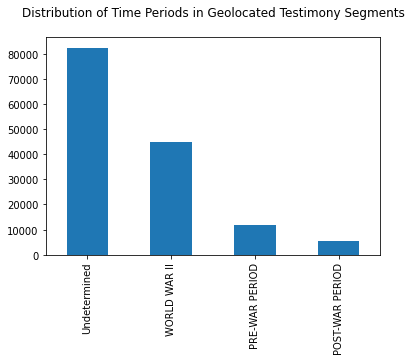
Using this method, 42.89 percent of geolocated text segments were categorized into the time periods “Pre-War Period”, “World War II” and “Post-War Period”. 57.11 percent of text segments were not able to be categorized using metadata. These periods were then used to create three maps of the dispersion of sentiment before, during and after World War II.
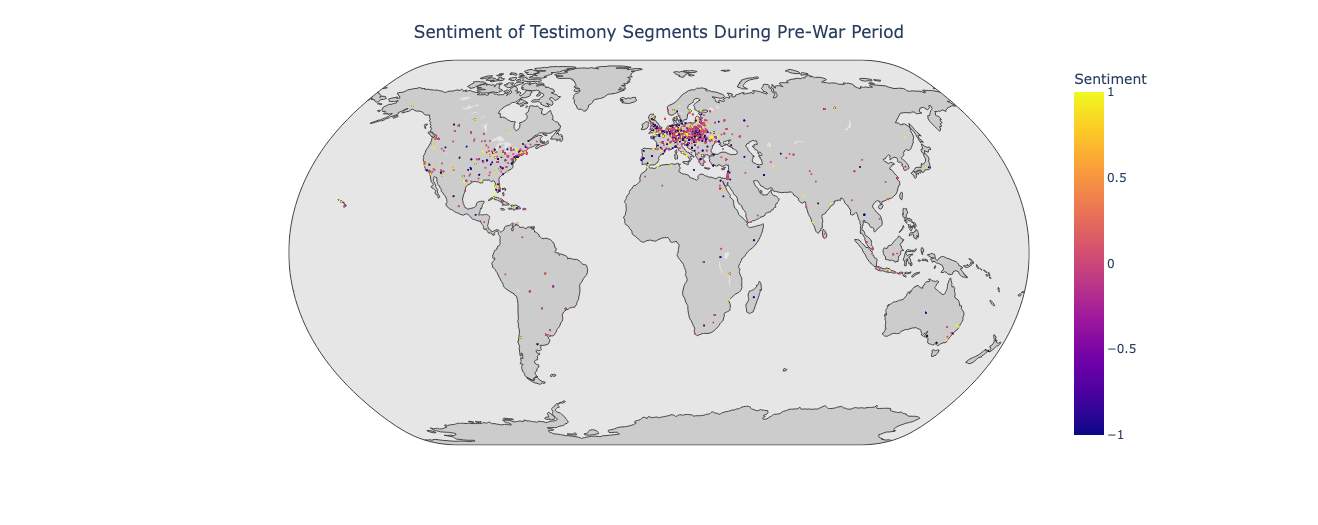
Visual inspection of the map of testimony segments leading up to World War II suggests that there is a nucleus of negative sentiment near Krakow in Poland, which was taken by Germany at the beginning of World War II.
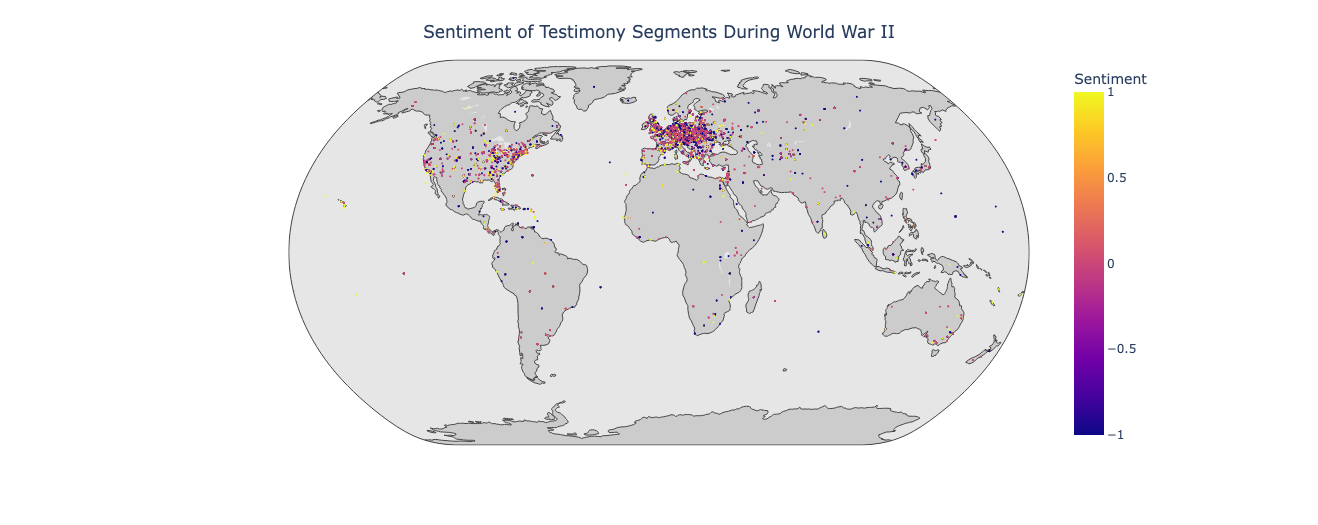
In testimony segments tagged as occurring during World War II, the distribution of negative and neutral sentiment is spread across much of Northern Europe. There are also more instances of negative sentiment around the world.
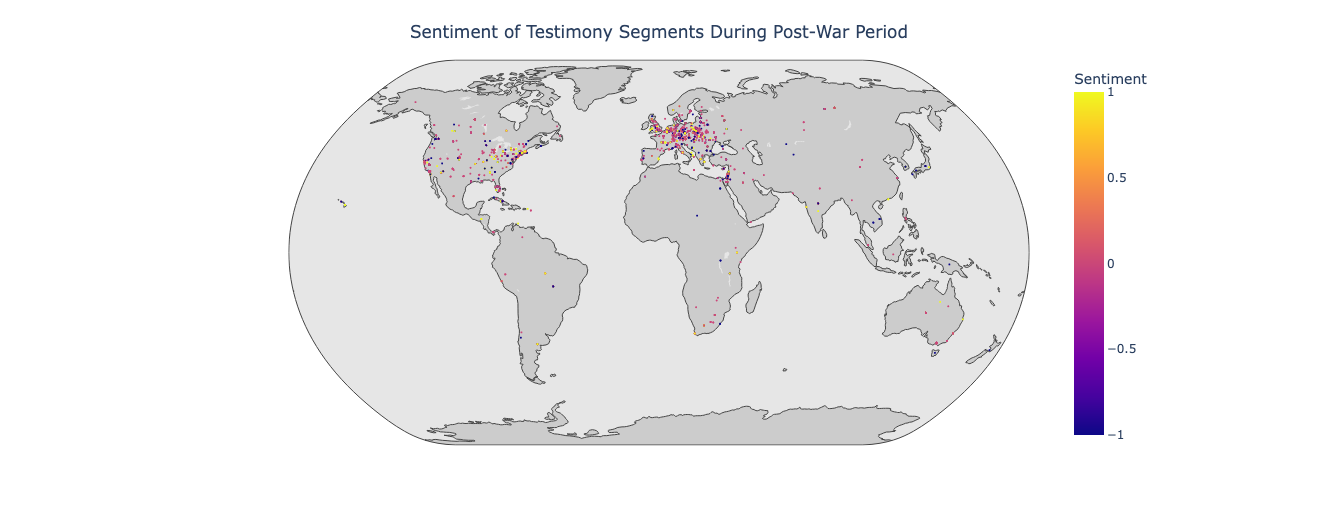
In the data tagged as ‘Post-War Period’ there appears to be considerably less negative sentiment.
5. Discussion
In order to compare the agreement between approaches, we performed and visualized a cross-model comparison on the full dataset. Because of the highly skewed results from the Naive Bayes approach toward the labeling of sentiments as “Negative”, we opted to focus on Vader, TextBlob, and Logistic Regression.

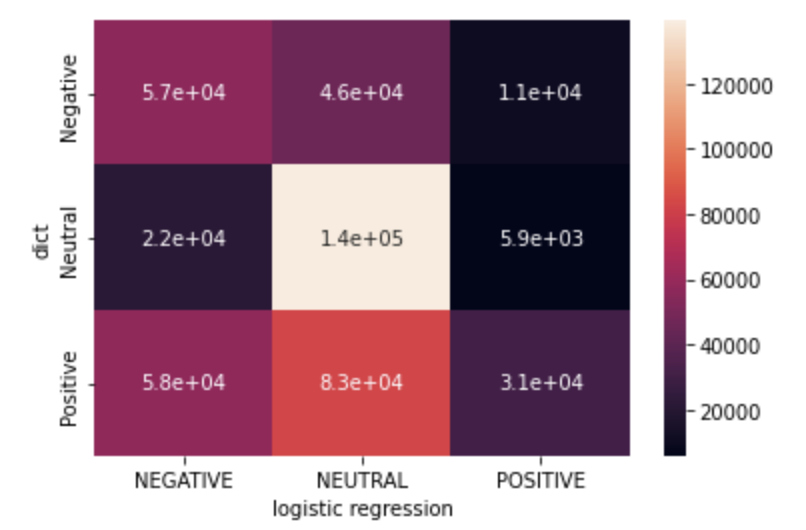
It is evident from the data visualization that the most agreement lies in the “Neutral” labels, followed by “Positive” and then “Negative. However, the Logistic Regression model incorrectly labels more sentiments as “Neutral” when Vader labels them as “Positive”.
The limited labeled data that we had proved to be a hindrance in our use of non-dictionary based methods. Because we only had around 650 labeled testimony segments that were being used to train the data, the trained algorithms could not learn to predict sentiments very accurately. For example, Naive Bayes had a very hard time identifying sentiments that were labeled as “Positive” to the extent that no transcript segments from the testing data were labeled “Positive” at all. When the model was ran on the entire dataset, the majority of positively labeled segments were segments including inherently and indisputably very positive words (e.g. “laugh”, “wonderful”).
While GPT-3 is powerful and produced significantly more accurate results compared to the other approaches, limitations presented themselves in different ways. Since GPT-3 requires payment to access their models, the number of times it could be run was restricted. Though 70% accuracy was better than the other models, the accuracy of the model can still be improved. If given more computing resources or a budget, one way to improve the model’s accuracy is to fine tune the model with annotated data. However, there may also be other ways to improve the model’s accuracy and other factors to consider before producing sufficiently large manually annotated dataset.
Owing to the emotional complexity of Holocaust testimonies, future research should consider what is the unit of analysis in sentiment analysis, whether the process of sentiment analysis can be broken down into smaller steps, and whether or not positivity and negativity are mutually exclusive. These questions should be answered before producing an annotated data set, because the answer to these questions will determine what data will be needed and how that data should be structured.
When annotating the testimonies, there were several difficult text passages that could not be easily categorized as negative, positive or neutral. Consider the following example:
“No, no. I was always hoping to see my family. And in fact, I never forget, one kind British soldier came, and he brought us stuff. And he gave me a box of sardines. [CRYING] And my sister was very fond of sardines. And I hid it, to bring it home for her. [PAUSES FOR 4 SECONDS]” (File num: 5496; Time Stamp: 0:41:00)
In a complex text segment such as this, it is difficult for an NLP model to analyze the sentiment. This example includes “[CRYING]” which is usually negative, and it does not include many overtly positive terms. However, it does describe one “kind British soldier” and how the speaker’s sister was “very fond of sardines.” With this information, a human coder might label this text segment as “Positive”. After reading further, one might question why the speaker felt the need to hide the sardines. Based on this additional information, a human annotator might determine that the sentiment is actually negative. In our dataset, this was manually labeled positive. GPT-3 labeled the segment as neutral.
In examples like these it is not clear that text segments have a single sentiment. It would be reasonable to characterize the above example as both positive and and somewhat negative. This is the case for many Holocaust testimonies. Consider the following example:
Of course, I was very thin. I was somewhere around 90 pounds. My mental, my mental state was very good. I’ve never lost hope. I was not in a depression. I was– no fear of death at all. That was a, a sister of mine. I’ve seen it so many times. I’ve been so close to it. (File num: 18575; Time Stamp: 2:49:00)
Like the previous text segment, this segment is difficult to analyze. On one hand, it appears very positive, as the speaker reiterates that their mental health was good and that they were not depressed. However, the speaker also describes death as “a sister of mine” and something they have “seen so many times”. Knowing that the context of this statement is the Holocaust, it does not feel ethical to categorize this text segment as simply “Positive” or “Neutral”.
From an NLP perspective, one possible solution is to break the segment down into smaller sentences, and analyze each separately. In this case “…my mental state was very good”, “I’ve never lost hope” and “I was not in a depression” might all be tagged positive. However, if we were to do this, the sentence “That was a, a sister of mine.” would not be fully interpretable. Similarly , the sentence, “I’ve seen it so many times” lacks context on its own. Without the entirety of the text segment, these sentences lack the information required to be analyzed for sentiment.
Another possible solution is to separate positive and negative labels from one another. Consider the following example:
But the administration seemed to know when those things were going to happen, or at least the principal did. And I remember many times the principal walking into class and calling me out for whatever reason, and to wind up in the infirmary, or hidden in his office, or whatever, so that whenever there was a search they wouldn’t see that I was a Jewish boy. (File num: 5810; Time Stamp: 0:47:00)
This text segment discusses how the principal of a school found excuses to hide the speaker from police searching for Jewish children. Such an example is especially difficult to analyze because it does not include any strongly positive or negative words. Nevertheless, it does not feel entirely neutral. When reading an example like this, it is possible to think that it is both positive and negative. On one hand, it is positive that the principal protected the student and that this action left an impression on the speaker that they remember clearly. However, the fact that the speaker had to be hidden away is also negative. If I were to causally describe the sentiment expressed in this text segment I would describe it as somewhat positive, somewhat negative, and somewhat neutral. If positive and negative sentiment scores were separated from one another in the training data, a transformer based model could be trained to predict how positive and how negative a text segment is.
Another possible approach is to use the text generation capabilities of transform models to not only predict sentiment but to predict emotional reasoning about sentiment. In other NLP tasks, it has been shown that transformer models are capable of predicting the correct answer to a complex question by breaking the process down into smaller sub tasks. For example, in prompt programing, serialized reasoning breaks a complex question into a series of simpler multiple choice questions. Building on the answers to the series of multiple choice questions, the transformer model is capable of arriving at an answer that it wouldn’t be able to arrive at if the question was not broken down.
An analogous strategy could be developed for emotional reasoning about testimonies. Given a testimony, a transformer model could be trained to isolate the most negative and most positive elements of the testimony, and weigh those elements against one another before producing a final classification. Training a model to do a task like this requires more sophisticated prompt engineering or more detailed training data.
Another potential pitfall of sentiment analysis is that it is unclear what unit of text contains sentiment. A sentiment does not clearly correspond to a single sentence and the amount of sentiments in text is not directly proportional to the length of text. It is possible for some sentences to contain multiple sentiments, just as it is possible for entire sentences to lack a determinable sentiment. For example one text segment we encountered when annotating the testimonies was the following short sentence:
One woman survived.
(File num: 895 ; Time Stamp: 0:30:00)
With such little information, it is difficult to decide if the sentiment is positive or negative or neutral. Is the speaker celebrating the survival of one woman, lamenting how many others were lost, or simply reporting a fact? In human interpretation it is common to look for additional context to confirm or disconfirm an interpretation, either by looking backward in the text, or forward.
One possible solution is to train a transformer model to not only determine positive, negative or neutral sentiment, but also to classify whether or not the text segment has enough information to convey sentiment. A sentiment analysis algorithm could be designed to classify sentences that require more context to interpret as “underdetermined” or “ambiguous” for example. Then the sentiment analysis algorithm could look forward or backward in the document to provide more context to the segment. This procedure could be repeated until the algorithm determines a sentiment score. This approach may run the risk of double counting sentiments. Nevertheless, this approach may better accord with human approaches to emotional reasoning than the method of analyzing each segment independently.
Future research with transformer models will likely benefit from a mix of manual data annotation, prompt engineering, and model fine-tuning. Before one begins the process of manually annotating data and training the model, the research should break the process of sentiment analysis (or any type of classification) down into smaller pieces. Thoughtful consideration of the sentiment analysis pipeline involves asking several questions. What is the base unit of analysis? Does sentiment analysis require solving sub tasks before producing a sentiment score? If so, what are these subtasks and will the model need manually annotated examples? What to do if sentiments are not simply positive, negative or neutral? Is positivity, negativity, or neutrality an ordinal variable? Should positivity and negativity be measured separately? Are there text segments that are neither positive, negative or neutral in the data? What should the algorithm do in such instances? Answers to these questions likely depend on the specific material being analyzed.
6. Conclusion
Improving sentiment analysis in the context of the digital humanities still has a long way to go. There are a few potential directions in particular that are notably relevant to the analysis approaches that we took. First, at a very basic level, if considering dictionary-based approaches, we can continue improving the manually labeled lexicons to account for the historical and cultural context of the Holocaust. A lot of non-English words are still unable to be labeled properly, and words that hold different meanings and weight given the events of the Holocaust should be labeled as such. Second, for using data to train datasets, manually labeling additional transcripts to increase the number of training data available will be helpful to improving the accuracy of the algorithm, as we currently are training on only approximately 650 transcript segments out of 864 total transcripts. This is a small number, and considering that we have seen the accuracy of the algorithm improve throughout the process as we increased the available training data, labeling more data to train the model would undoubtedly continue to improve the accuracy of the algorithms’ respective outputs. Further fine-tuning of accessible yet more advanced tools such as GPT-2 is another promising prospective future plan of action in order to progress with this research. Finally, we can continue to explore the contextual effectiveness and overall accuracy of other models, such as SBERT.
Works Cited
Beorn, Waitman & Cole, Tim & GIGLIOTTI, SIMONE & Giordano, Alberto & Holian, Anna & Jaskot, Paul & Knowles, Anne & MASUROVSKY, MARC & Steiner, Erik. (2009). Geographies Of The Holocaust. Geographical Review. 99. 10.1111/j.1931-0846.2009.tb00447.x.
Blanke, Tobias & Bryant, Michael & Hedges, Mark. (2020). Understanding memories of the Holocaust—A new approach to neural networks in the digital humanities. Digital Scholarship in the Humanities. 35. 17-33. 10.1093/llc/fqy082.
Bonta, Venkateswarlu & Kumaresh, Nandhini & Janardhan, N.. (2019). A Comprehensive Study on Lexicon Based Approaches for Sentimen t Analysis. Asian Journal of Computer Science and Technology. 8. 1-6. 10.51983/ajcst-2019.8.S2.2037.
Kushner, T.. (2006). “Holocaust Testimony, Ethics, and the Problem of Representation.” Poetics Today. 27. 275-295. 10.1215/03335372-2005-004.
Reynolds, Laria & McDonell, Kyle. (2021). Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm. 1-7. 10.1145/3411763.3451760.