Note on Narratives of Transformation
Note to self: when writing a narrative account of a historical development or transformation, always consider the population for whom it transformed for the most, and form whom it transformed for the least. This reflection is in part a response to Davis (2009) Managed by the Markets: How Finance Re-Shaped America. In Davis’ historical account, Davis focuses on how the character of “the social institution of the corporation” seems to have changed as a result of financialization. Davis does not stop to ask for whom the corporate institution has changed the most, and for whom it has changed the least. Instead, the narrative Davis pursues is a narrative of how the institution of the corporation lost its sense of paternal responsibility to its employees. Regardless of one’s political stance, I think it is important to consider that there were always those for whom the institution of the corporation never performed paternal responsibilities and, likewise, there are still those for whom corporations do perform their responsibilities. Only telling one story of transformation is likely distortive and potentially alienating.
Python for finance
I bought “Python for Finance” by O’Reilly Press from Amazon the other day. Today I am getting started with the book, trying follow along with as many of code snippets as possible.
In the beginning chapters of the book, I am struck by how difficult it is to get the basic environment ready for coding. Before you learn how to do 1+4, you have to set up a containerized cloud instance protected by an SSH key. In the past, I’ve just run python on my computer, but this book requires setting up your Python environment in a containerized app on the cloud. A few thing struck me about the process.
First, there is the whole notion of containerization. Has anybody written about containerships and containerized apps? The cloud infrastructure seems to be an attempt to create modularity within software development. The idea behind containerized apps is that the you can create a self-contained application that is not dependent on the file structure of any particular machine, and thus can be deployed on any machine. In finance, I assume that the rationale behind containerization is two fold, first as a way to leverage the low costs of cloud infrastructure, and second as a way to take advantage location. By making financial programs independent from local file structures, it is possible to test and develop containerized apps on cheaper server locations while deploying them as close as possible to the exchange on expensive digital real-estate.
Second, security is stressed in setting up the coding environment. Unlike other books in programing with Python, this book requires encrypting the coding environment with SSH key pairs. Because placing programs on servers means that the data may be exposed to hackers, following security measures to hide the data from others is an essential practice.
It is interesting that these sophisticated command line methods are presented before the most basic principles of programming in Python. Only after setting up a secure containerized instance does the author introduce the reader to simple Python operations like addition, subtraction, and multiplication.
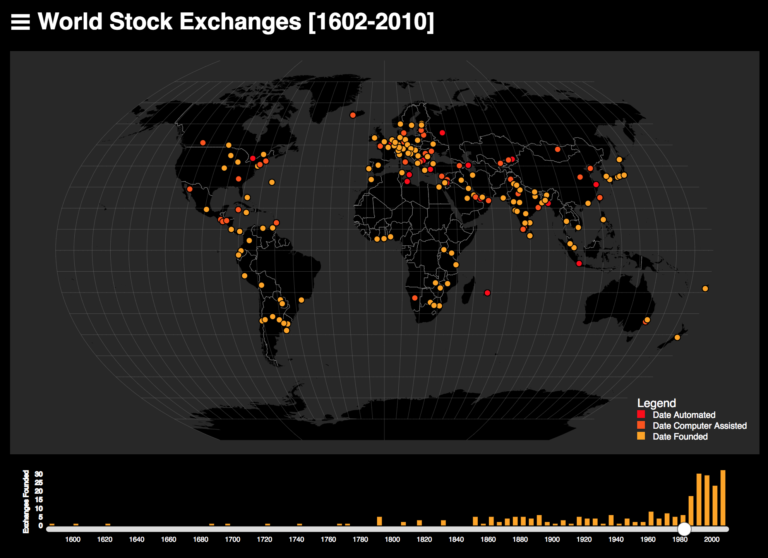
World Stock Exchanges
For Introduction to Digital Methods & Scholarship (INF STD 289) I developed a programmatic method to structure unstructured historical data regarding stock exchanges. Using Natural Language Processing (NLP) I extracted relevant dates and geographic locations. This data was then geocoded such that the locations and dates of historic stock exchanges could be mapped. My collaborator Laura Jara helped develop a controlled vocabulary to classify stock exchanges and, using a mix of programmatic and manual methods we annotated the data to identify shifts from face-to-face markets toward computerized exchanges. Read More
Securities Industry Automation Corporation’s Data Processing Equipment

The New York Stock Exchange formed the The Securities Industry Automation Corporation (SIAC) to automated order routing in 1972. The NYSE boasted in its 1973 Annual Report that, “SIAC data processing equipment, including 10 major computer systems, makes it one of the largest data processing service operations in the United States in terms of size.”
I Wonder if Adorno Would Hate This?
Thinking a lot about Fourier transform, compositionality, interference, and what it means for the process of history, as layers of the present invariably distort the past, even when the past is preserved in fragments of the present.